

Summary
This blog explains that a successful POC should be treated as a step toward production, with deployment, operations, and scaling planned from the start rather than after the prototype succeeds. It highlights practical ways to do that, including building modular components, using standard integrations, setting up MLOps and DevOps practices early, defining operational ownership, addressing security and compliance before launch, and planning for scale in both technical and cost terms. It also emphasizes the role of platforms, toolchains, templates, and collaboration tools in reducing delays and improving consistency.
Overall, the piece argues that with the right mix of people, process, and technology, organizations can move from POC to production at scale more effectively and avoid leaving promising ideas stuck in the POC stage.
A truly production-oriented mindset treats a POC as a stepping-stone, not a throwaway. To fast-track into production, proactively design a path for deployment, operations, and scaling even as you build the prototype.
Think of it as parallel workstreams: one stream is developing the solution; another is developing the deployment plan.
Some actionable steps:
Architect with modularity and integration in mind
Wherever possible, build the POC components in a modular way that can plug into larger systems.
For example, if you develop a machine learning model, wrap it behind an API even in the prototype (perhaps using a simple Flask app or cloud function).
Integrating it into a production application later is easier – you’ve already exposed it as a service. Similarly, use standard interfaces for data (APIs, message queues, etc.) rather than bespoke hacks.
For example, a team can simulate during the pilot how the prototype’s outputs will integrate with existing enterprise systems and workflows using standard interfaces such as APIs, webhooks, or message queues. Validating those integration points early helps demonstrate that the solution can fit into the broader operating environment, making production rollout far more straightforward.
TOP TIP: Design POCs as if they will join an ecosystem of tools and processes, not exist in isolation.
Establish MLOps/DevOps pipelines for deployment
Set up a continuous integration/continuous deployment (CI/CD) pipeline even for the pilot, if feasible.
This might include automated tests (did the model training code run successfully? are data transformations producing expected results?), infrastructure-as-code scripts for provisioning environments, and containerization of components.
Using technologies like Docker and Kubernetes can greatly simplify promotion to production – you can take the same container image from testing into production with greater consistency. If your team is new to these, consider starting with simpler automation: e.g., use a Git repository; when code is pushed, have it automatically run on a staging server.
TOP TIP: The more you treat the POC like production software, the less rework later.
Additionally, plan for model monitoring from the outset: decide what metrics you’ll track in production (accuracy, response time, etc.) and build hooks to collect those. This ensures that once deployed, you can quickly catch issues like model drift or performance degradation.
Define an operational owner and support model
Well before go-live, identify who will own the system in production. Is it the Data Science team, an IT application team, or maybe a new AI Ops function?
Involve that operations team in the later stages of the POC testing. Develop runbooks or playbooks for how the solution will be maintained (e.g. “model retraining will occur monthly with dataset X; monitor dashboard Y for errors; contact person Z for issues”).
If you plan this in advance, you can even do a “fire drill” during a pilot extension – simulate an issue and see if your monitoring catches it and the team knows how to respond.
This kind of preparation can cut down the transition time significantly, because the ops team will be confident and ready to take over as soon as it launches, rather than needing weeks of handover.
Address security, compliance, and risk before launch
Proactively run your prototype (and its deployment architecture) by the necessary governance forums – security review, data privacy, compliance, etc. It’s much faster to adjust mid-development than to have compliance block deployment at the last minute.
For example, if your solution uses a third-party AI API, legal might need to vet data usage terms; do that early.
If it’s a model making decisions on customers, maybe you need an explainability report or bias audit – build that into the POC scope.
Gartner’s prediction that so many POCs will be abandoned due to “inadequate risk controls” should be a warning: don’t ignore risk management until after the POC. Instead, include a governance checklist in your acceleration plan.
That could mean ensuring data used has proper consent, verifying that model outputs comply with regulations (e.g. no unlawful profiling), and having an AI ethics review if applicable.
Though this might sound like extra work, it ultimately speeds up production rollout by preventing nasty surprises.
Optimize for scale (technical and cost)
If your POC is successful, usage will grow – more data, more users, maybe tighter latency requirements. Plan for this scaling curve.
This could involve choosing a scalable cloud service for hosting (so you can just allocate more resources rather than redesign), using efficient algorithms (maybe distill a large ML model into a smaller one if you expect heavy traffic), and estimating cloud costs for projected workloads.
Where possible, do a trial run with larger data volumes to identify bottlenecks. Some teams run a “day in the life” simulation in staging, feeding the system a full day’s worth of transactions to see how it holds up. Also consider multi-region or high-availability setups if the application is critical.
The sooner you tackle these, the less technical debt accrues. A common pitfall is proving value in a pilot, only to discover that significant re-engineering is needed before the solution can handle production scale.
Instead, aim for built-in scalability by using cloud-native, elastic components and design patterns that support growth without major redesign.
If cost is a concern, engage your cloud architects or FinOps team to figure out optimizations (e.g. use spot instances, or optimize inference throughput). The faster you solve these, the faster and more smoothly you can launch enterprise-wide.
In summary, thorough planning for deployment and operations is a force multiplier for POC acceleration.
Organizations that bake in the last-mile thinking from the start often deploy in weeks, not quarters after the POC concludes, because there’s no massive refactoring or organizational scramble required.
Leverage the right platforms, tools, and templates to speed execution
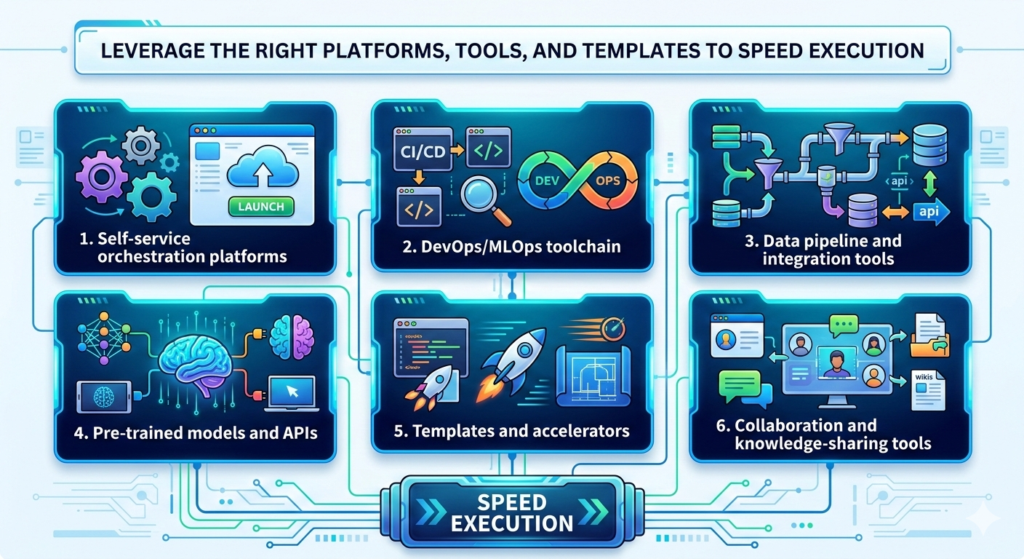
Finally, an acceleration plan wouldn’t be complete without mentioning technology enablers.
There are many tools and platforms that can significantly reduce the time and effort to go from prototype to production.
The key is to choose those that fit your organization’s context (and of course, to avoid fragmenting into too many tools – stick to a well-integrated stack).
Here are some categories and examples:
1. Self-service orchestration platforms
These are end-to-end solutions designed to streamline data product development.
Calibo’s Self-Service Orchestration Platform provides a unified environment where teams can define, design, develop, and deploy data/AI products with a governed workflow.
Such platforms often come with pre-built integrations (Calibo offers 150+ integrations ranging from AWS and Azure to Snowflake, Databricks, etc.) which means your prototype can easily connect to different databases or services without custom glue code.
Calibo’s Data Platform—the Data Pipeline Studio—covers data capabilities end-to-end, from data ingestion to data visualization.
On the DevOps side, teams can develop POCs and move through the phases of the SDLC—develop, execute CI/CD, test, and promote to production.
They also promote reusability—components like data and CI/CD pipelines, ML features, or UI modules can be templatized and reused across projects.
By orchestrating the full lifecycle in one place, you eliminate a lot of hand-offs and delays. For organizations aiming to reduce friction across the lifecycle, a self-service, governed platform can significantly improve speed and consistency.
2. DevOps/MLOps toolchain
If a full platform is not the right fit, organizations can still assemble an effective DevOps and MLOps toolchain. Version control systems and CI/CD pipelines are fundamental – they ensure every change is tracked and deployments can be automated.
For machine learning, consider MLOps tools for experiment tracking, model registry, and deployment pipelines. These provide a scaffold so that moving a model from a notebook to an API or batch job is faster and less error-prone.
Also, containerization via Docker and orchestration with Kubernetes or serverless frameworks can drastically cut down environment setup time – you package your app once and run it anywhere.
The idea is to use industry-standard tools to avoid reinventing wheels; this not only speeds up the POC-to-prod path but also makes it easier to hire talent (since they’ll likely know the tools).
3. Data pipeline and integration tools
Setting up robust data flows quickly is easier with modern ELT/ETL solutions.
Tools like Fivetran or Airbyte can quickly connect sources and load data into your analytics environment without custom coding. Platforms like Calibo can orchestrate complex workflows on schedules.
The acceleration principle here is to use pre-built connectors and pipelines rather than manual scripts.
Some organizations maintain a library of pipeline templates – e.g. a template for ingesting CSV files from an SFTP, or a template for joining customer data with transaction data. By reusing these, each new project doesn’t start from scratch.
4. Pre-trained models and APIs
In the AI domain, one way to jumpstart a project is to use existing models or AI services.
For example, if you need OCR or speech-to-text in your solution, calling an API from Google or Azure might be far quicker than developing your own model.
Likewise, for generative AI, using a foundation model via an API (OpenAI, etc.) can get you to a POC in days. Just be mindful of data governance (ensure you’re allowed to send data to those APIs, or use privacy features).
The trade-off with third-party models is often less control, but if it fits your use case, it can shave months off development.
You can always swap in a custom model later if needed, but using a proven solution initially accelerates getting something working in production.
5. Templates and accelerators
Encourage your teams to create and use templates for common project elements. This could include infrastructure-as-code templates (e.g. a Terraform template to deploy a standard data science environment, so spinning up new dev/test/prod environments is fast and consistent), policy templates as mentioned for governance, and even business process templates (checklists for things like model validation, deployment readiness, etc.).
Many consulting firms and vendors provide accelerators – for instance, an “AI use case canvas” template to plan projects, or pre-built solution blueprints for things like customer churn prediction.
Utilize these to cut down the brainstorming and planning time. In some organizations, teams prepare standard templates for pilot evaluation, integration planning, and ROI assessment. This allows them to quickly consolidate results and make a production decision as soon as the pilot concludes.
As a result, teams can quickly compile results, integration specifications, and ROI calculations to support a production decision – essentially productizing the pilot insights immediately.
6. Collaboration and knowledge-sharing tools
An often overlooked accelerator is simply enabling fast collaboration. Use tools like Slack/Teams channels for the project to speed up communication. Maintain a shared documentation space (Confluence, Notion, etc.) for the project where all stakeholders can see updates, requirements, and decisions in real-time.
This avoids lengthy email chains and keeps everyone aligned, which indirectly but significantly accelerates execution by reducing miscommunications and duplicate efforts.
TOP TIP: In selecting tools, beware of analysis paralysis, don’t spend forever evaluating options. It’s usually better to pick a reasonably good tool and standardize it than to delay projects looking for the “perfect” solution.
Also, integrate tools to avoid silos; for instance, connect your task tracking (JIRA) with your version control and CI so that everything is traceable. Integration of the toolchain itself can save time (no manual handoffs between systems). Platforms such as Calibo are designed to bring these capabilities together in a more integrated way.
Lastly, remember that tools amplify process. If you have a poor process, tools alone won’t save you – they might just help you do the wrong things faster. So combine the right technology with the right methodology (like the steps we’ve discussed above).
When you have both, you create a powerful acceleration engine.
In practice, organizations that combine the right platform, team culture, and delivery process often see meaningful reductions in development and deployment time.
The end goal is to make moving from idea to outcome not a special ordeal, but a routine “innovation assembly line” that reliably churns out new business capabilities.
Best practices to avoid the POC graveyard
Avoiding the POC graveyard and accelerating time-to-value is challenging, but entirely achievable with the right approach. Here are the key takeaways and best practices to remember:
- Start with the why and how: Don’t kick off any data/AI prototype without a clear business problem, defined success metrics, and an executive sponsor.
- Get your data and architecture ready: Early in the project, assess data availability, quality, and pipeline needs – within the context of your selected use case(s). Fix data hygiene issues and set up at least a basic pipeline so the prototype runs on reliable, updated data.
- Adopt a “POC to production” framework: Establish a repeatable process or checklist to guide projects from ideation to deployment. Include steps for prioritization (to pick high-value projects), governance checks (privacy/security review), and operational planning (post-POC support model).
- Leverage accelerators (platforms, templates, tools): Speed up development with proven tools and reusable components. Use orchestration platforms or integrated toolchains to eliminate friction in moving code and data between dev, test, and prod.
- Balance innovation with governance: Encourage experimentation and fast iteration (fail fast!), but within guardrails. Create a sandbox with self-service access that’s monitored and secure. Implement policies-as-code so compliance is continuous, not an afterthought.
- Plan the last mile from the start: Don’t wait until after a “successful POC” to think about deployment. Define the path to production early – architecture, integrations, who owns it, how it will be monitored, and how it will scale.
- Cultivate an agile, learning culture: Foster a culture where the organization is willing to test, learn, and iterate rapidly. Celebrate learning from failed POCs as much as successes. The companies that thrive with AI are those that “ship, get feedback, and refine in tight loops”, rather than chasing mythical perfect solutions on the first try. Make experimentation continuous, but always with a line of sight to production deployment for the winners.
To conclude, don’t let great ideas die as experiments. With the right orchestration (people, process, technology), you can consistently turn data innovation into operational reality, avoiding the POC graveyard altogether.
FAQ
Q: How do I decide which POCs to continue or cut?
A: Implement a prioritization scorecard or matrix to evaluate POCs on business value vs. effort/risk. POCs that score high on value and reasonably on feasibility should be prioritized for production investment.
Q: We lack specialized AI talent for productionizing models. How can we bridge that gap quickly?
A: Focus on reducing complexity rather than solving everything with specialist hiring. Standardize delivery practices, automate as much as possible, and use platforms or toolchains that simplify deployment, monitoring, and governance. In parallel, involve the teams who will operate the solution in production early in the process so ownership does not become a bottleneck later. Where needed, bring in targeted external expertise to accelerate the first few deployments while building internal capability over time.
Q: How can we ensure our rapid prototyping doesn’t create security or compliance risks?
A: Build governance into the process from the start. Use secure sandbox environments, involve security and compliance teams early, and make sure data access, privacy, and policy requirements are considered during development rather than just before launch. Where possible, use masked or synthetic data in early testing and rely on approved platforms, tools, and controls such as encryption, role-based access, and audit logging. Rapid experimentation does not have to mean weak governance if the right guardrails are in place from day one.
Trending articles

Data orchestration: why modern enterprises need a data orchestration platform
Data is pouring in from myriad sources—cloud applications, IoT sensors, customer interactions, legacy databases—yet without proper coordination, much of it remains untapped potential. This is where data orchestration comes in.

How Enterprise Architects can get more support for technology led innovation
Enterprise Architects are increasingly vital as guides for technology-led innovation, but they often struggle with obstacles like siloed teams, misaligned priorities, outdated governance, and unclear strategic value. The blog outlines six core challenges—stakeholder engagement, tool selection, IT-business integration, security compliance, operational balance, and sustaining innovation—and offers a proactive roadmap: embrace a “fail fast, learn fast” mindset; align product roadmaps with enterprise architecture; build shared, modular platforms; and adopt agile governance supported by orchestration tooling.

Why combine an Internal Developer Portal and a Data Fabric Studio?
Discover how to combine Internal Developer Portal and Data Fabric for enhanced efficiency in software development and data engineering.

The differences between data mesh vs data fabric
Explore the differences of data mesh data fabric and discover how these concepts shape the evolving tech landscape.